
Nowadays, a technology company without a data strategy is akin to a company not having a mobile plan five years ago – completely unacceptable. Around 2005, any company without “big data” was small potatoes. More recently, a company without [you name it]-as-a-service was woefully retrograde. Are technology companies a bunch of sheep that hew to the buzzwords du jour? Absolutely. Is it wise for a contemporary company to forgo a data strategy? Absolutely not.
The steam engine, electricity, and the computer revolution are the three most recent technological advances that have altered society. Technology luminaries like Kai-Fu Lee believe the impact of Artificial Intelligence (AI) will be just as disruptive (it’s almost impossible to avoid the minefield of these technology buzzwords) as the three aforementioned technologies. Lee believes that in the next 10-15 years, the safest jobs will be those that require humanism, like Psychiatry, Medical Care, and Fiction Writing. He doesn’t mean that other jobs will vanish, but the advances of AI will push workers towards aspects of their professions that haven’t been automated away. Perhaps Lee imagines a future where novelists outnumber radiologists.
Artificial Intelligence became an academic field in 1956 and lay fallow for much of the 50 years following its inception. Over the last ten years, advances in Deep Learning neural networks fueled a venture capital gold rush. All the big players in the industry now consider themselves AI companies. The incorporation of machine learning into the fabric of a technology company is not just the province of the big players. Companies like Sentrana (disclosure: I’m an advisor to Sentrana) build platforms enabling companies to become highly productive on AI & Analytics.
Sentrana offers a product called DeepCortex for developing and operationalizing AI & Analytical pipelines. DeepCortex aims to reduce friction by realizing data insights in these ways:
- Providing a collaborative environment to unify everyone on the team. Sharing assets with other users and reusing assets created by other users are dead simple.
- Streamlining many tasks of the AI & Analytics workflow, DeepCortex empowers teams to produce more analytics, more data science, and more data engineering than is possible with other tools. DeepCortex yields insights and usable models in a shorter time.
- Executing the entire Analytical workflow with scale and efficiency requires advanced DevOps chops. DeepCortex automates and streamlines much of the compute process to run large-scale experiments in parallel without having to rely on a DevOps Engineering team.
- Deploying trained models in production is a delicate and expensive collaboration between multiI-disciplinary teams of Data Engineers, Data Scientists/Modelers, ML Engineers, and IT Ops. DeepCortex bakes-in this cooperative process.
- DeepCortex provides a tightly integrated visual and programmatic interface to specify and execute Analytical & AI pipelines. The programmatic interface (in a familiar JupyterLab Notebook/IDE) operates seamlessly with all Data and Compute assets managed within DeepCortex, and can be flexibly manipulated via Python and DeepCortex’s Python-derived Domain Specific Language (DSL). In tandem, the architectural view of executable pipelines is seen and manipulated through a visual drag-and-drop interface. Together, these interfaces support the full lifecycle of analytics development – from Data Engineering to Model development to Pipeline construction and execution.
- A DeepCortex “asset” is an umbrella term that encompasses input data, engineered features, pipeline logic, operator logic, and fully-trained models. DeepCortex tracks the provenance of its assets, which enables auditing and backtracing. This built-in DeepCortex functionality allows teams to quickly compare the results of multiple experiments or track the results of deployed models.
DeepCortex supports the full spectrum from no-code to yes-code; if prebuilt objects are sufficient to meet one’s need, no coding is necessary. If one needs functionality that doesn’t already exist in DeepCortex, an object can be created in the DeepCortex IDE, named, and saved. These objects can also be shared with the larger community.
To put DeepCortex through its paces, I wanted to accomplish something non-trivial, but achievable. Additionally, I wanted to understand how the tool might streamline the work of multi-disciplinary technical teams like the ones I’ve managed that traversed the full Engineering Lifecycle. These teams comprised Developers, ETL/Data Engineering/Analytics, DevOps, and QA Engineers. The project I chose trains a model to recognize images in a file that I supply and then tests the model with another set of images.
More specifically, these are the high-level steps:
- Create an album of images used to train a model. I chose the well-known CIFAR-10 dataset that has ten classes of images: airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, trucks.
- Build a pipeline with five distinct components: album preparation, image pre-processing, neural network architecture specification, model training, model performance measurement. The gist of this pipeline is to take a dataset as input and go through some crazy deep learning, resulting in a model that recognizes the ten image classes from CIFAR-10 in a file its never seen before.
- Execute the pipeline.
- Evaluate the results.
- Rinse & Repeat – Go back to step #2, tweaking parameters in an attempt to improve results.
Step 1 – Building an Album
Training a computer vision classification AI model starts with an Album of labeled images, i.e., a collection of images with identifying annotations. In this case, one of the ten classes in the CIFAR-10 dataset (dog, cat, car, …) must accompany each image in the album.
The DeepCortex Getting Started Guide provides instructions for Album Creation and Image Uploading. Images must be uploaded from an AWS S3 bucket. An AWS Access Key, AWS Secret Key, and AWS Session Token must be provided. For more information about obtaining these temporary credentials, see this AWS documentation.
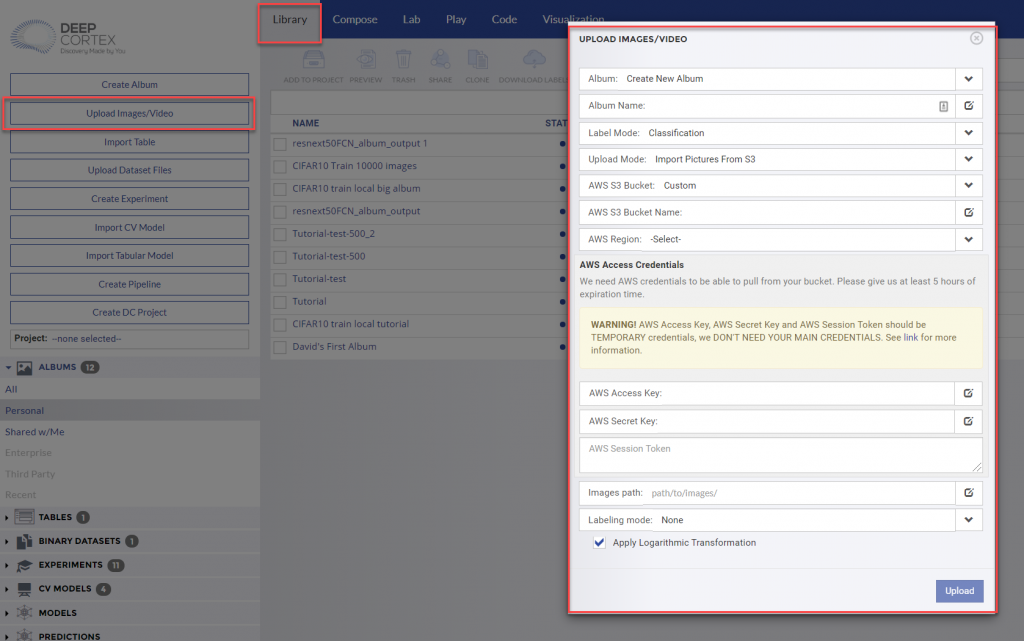
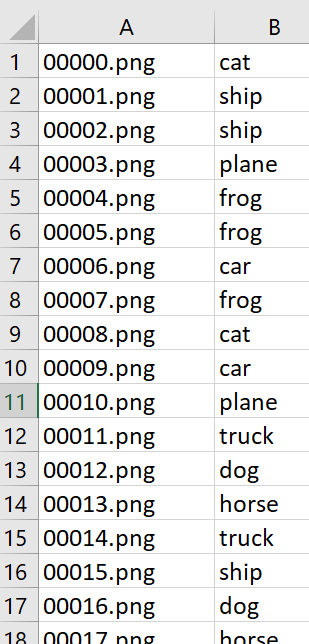
To add Labels/Annotations to the images, upload a .csv file with two columns of data: column 1 – image_name, column 2 – label_name. Note – if the image_name in the .csv file is not an exact match to the image name in the album, the labels for those images (from the .csv file) will not be updated in the album.
Step 2 – Building a Pipeline
This far-reaching Pipeline has five components. Sentrana provides a comprehensive Quick Start Guide that addresses most of the mechanics of Pipeline creation. Sentrana also has a full set of User Documentation that explores the parameters of Pipeline objects in greater detail and provides explanations of the rich DeepCortex feature set.

When I discussed my intentions with the Sentrana team, they smelled what I was cooking and had already prepared similar dishes. DeepCortex made it simple for Sentrana to share an appropriate pipeline with me that I cloned, modified, and reused, saving myself hours.
Step 3 – Executing the Pipeline
In data science lingo, executing a pipeline is called an “experiment.” A GPU instance, running at AWS or locally, is needed to train Deep Learning visual recognition models.
DeepCortex has two modes for running experiments:
- Run Interactively – Step through the pipeline, execute individual objects, and review results. This approach enables one to modify parameters along the way and re-execute already-run objects in the Pipeline.
- Not Run Interactively – This is the “one fell swoop” method where DeepCortex executes the entire Pipeline at the click of the ‘Run’ button.

Side note: It takes time to execute a complex Pipeline with a large data set and sufficient epochs. As a visual cue to show the operators in process, DeepCortex provides elegant, pulsing icons that change from yellow to green when completed.
Step 4 – Reviewing Results
Rather than repeating the methods of evaluation results from the DeepCortex User Documentation, this section outlines some of the experiments’ results and the changes I made to improve them.
The first experiment yielded miserable results. The model viewed everything as a deer.
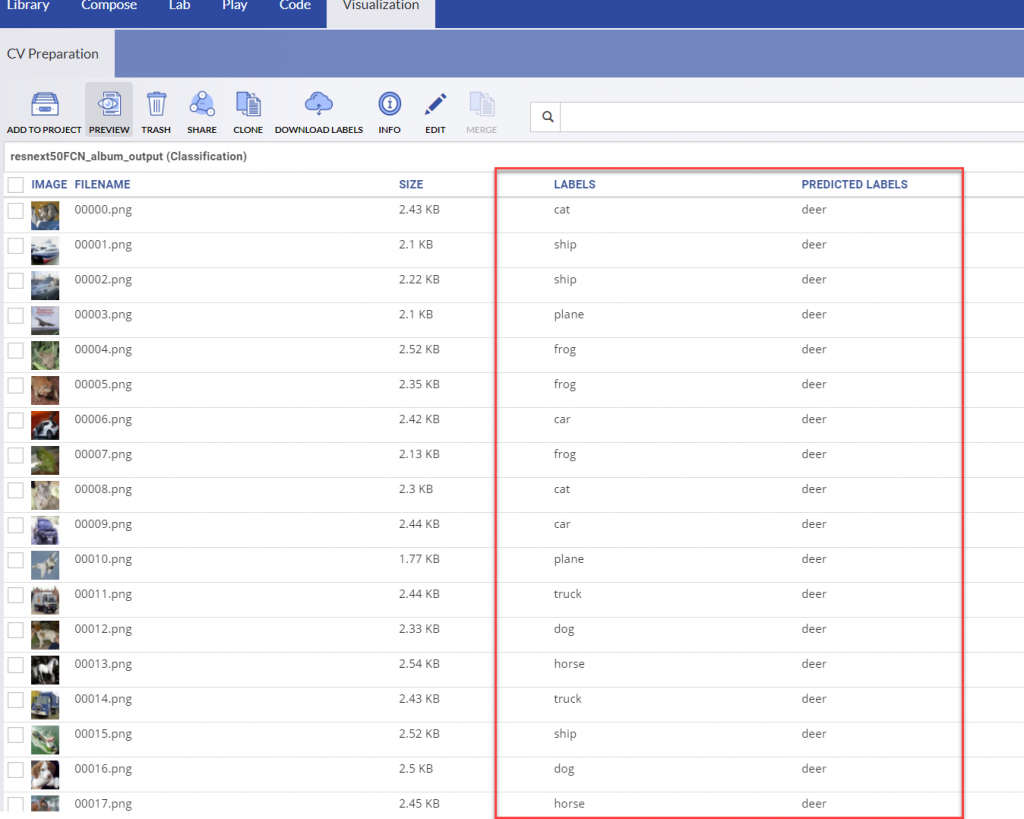
A few significant problems with the first experiment:
- Attempting to start small, I limited the training set to 500 images. A bit of quick Googling informs me that anything fewer than 10,000 images is insufficient to train a deep learning model, so I created a new, beefier album with 10,000 CIFAR-10 images. Note that in 2012, Stanford Professor Andrew Ng’s work that helped push the deep learning ball forward used 10 million YouTube images across 16,000 cores; in comparison, my 10,000 image album is hardly beefy.
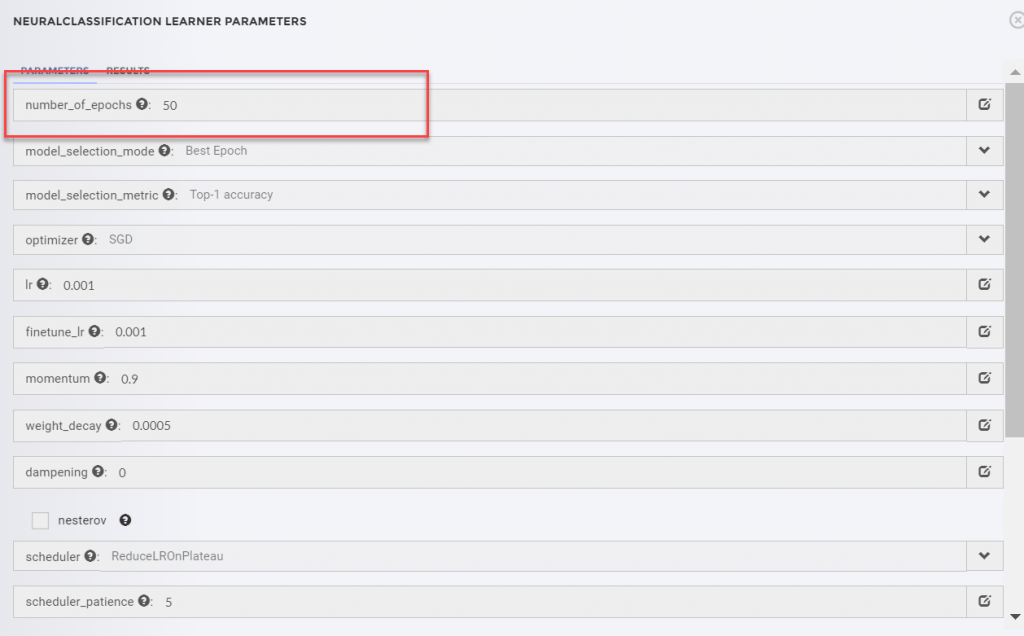
- I’d set the ‘number_of_epochs’ parameter of the Neural Classification Learner to just five epochs (a measure of the number of times all of the training vectors are used once to update the weights); this is too few to properly train the model so that it records the correct weights between nodes. I increased this parameter to 50 epochs.
3. The Resize operator transformed each image from 32×32 pixels to 256×256 pixels. This is a computationally expensive transformation that doesn’t yield better results. I modified this to simply ensure that each image is normalized to 32×32 pixels.

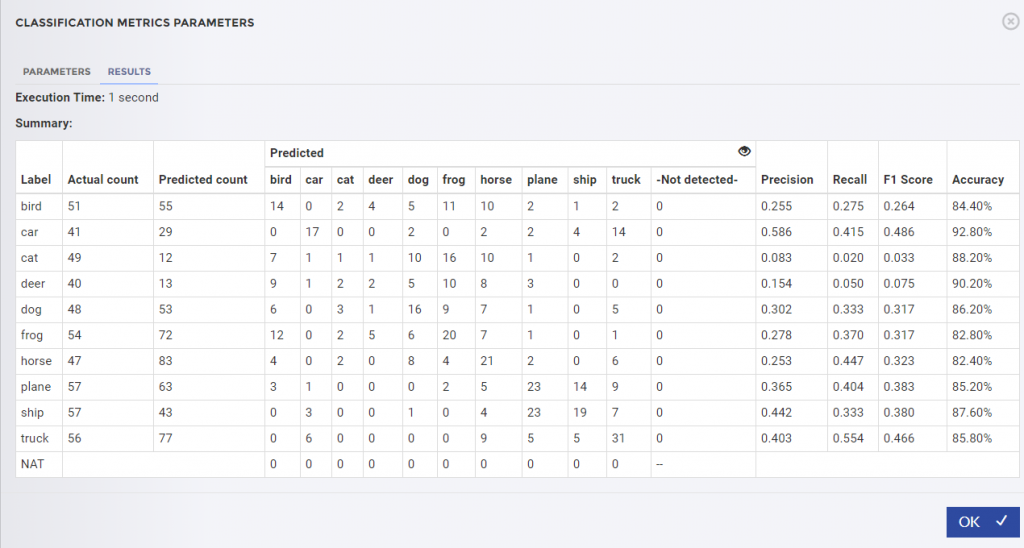
After making these changes and re-executing the Pipeline, the results were better but still disappointing. The results from the Classification Metrics operator show the F1 scores, a measure of the experiment’s accuracy, consistently below .5. Something was wrong, but I wasn’t sure what to tweak.
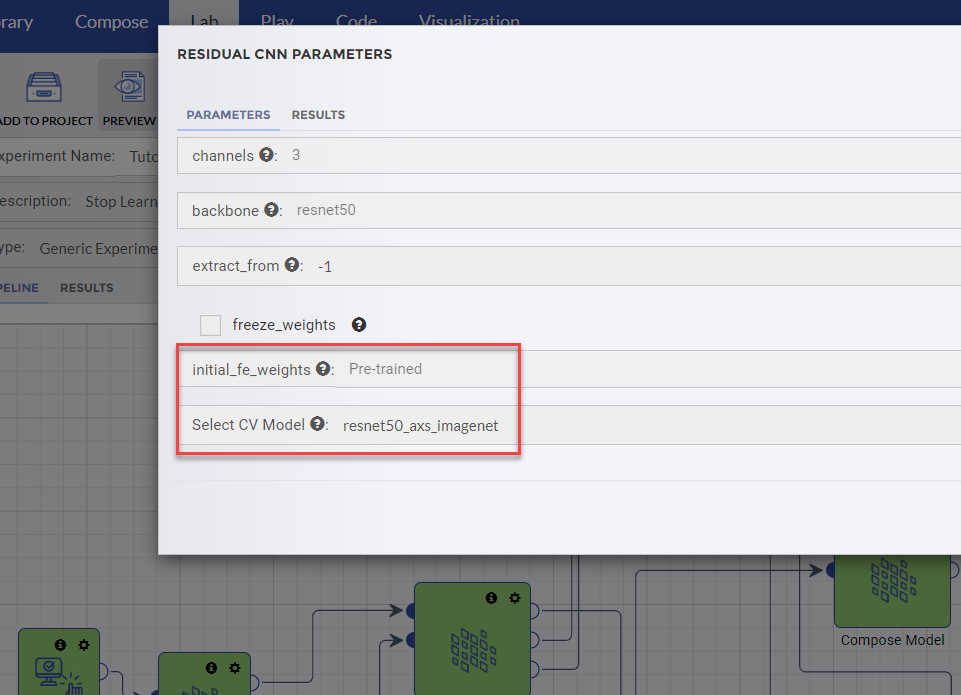
Up until this point, the folks at Sentrana had recommended that I bumble around on my own to determine if the strength of the DeepCortex documentation and supporting materials would ensure my self-sufficiency. Sensing my distress, they decided to toss me a bone. After about five seconds of listening to my problem, they correctly deduced that my pipeline was training the neural network from scratch instead of applying pre-trained weights. Optimizing a neural network involves establishing weights between the nodes of the neural network that yield the best results and then saving these weights. In my case, rather than grabbing the saved weights from another earlier experiment, I was reinventing the wheel each time. This is where DeepCortex’s built-in collaboration environment really rose above the rest. I was able to expand my team instantly, and within seconds my saviors at Sentrana jointly contributed to my AI pipeline, sharing a pre-trained model. The nifty thing about DeepCortex is that incorporating these weights requires nothing more than a small parameter change to the Residual CNN operator.
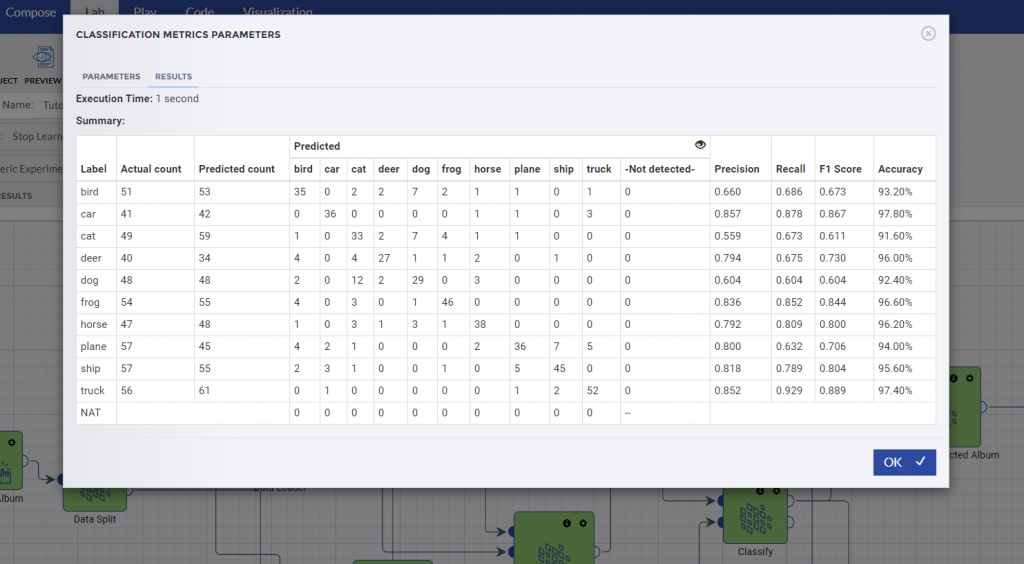
This time when I re-ran my experiment, the results were considerably better.
It’s exhilarating to make a shallow investment in Deep Learning and produce useful results so quickly. Although I leaned on the experts at Sentrana a couple of times, DeepCortex lives up to its promise as a tool that removes friction between IT and the other roles on Analytical teams. Although this exercise needed no additional coding, if I decide to blaze a new trail, operator creation in DeepCortex is well-supported and well-documented.
I’ve written extensively about nurturing capable employees to become expert problem-solvers and to achieve 10x performance. Until this experience with DeepCortex, I hadn’t considered the role of tools like this in enhancing performance. In this case, the simplicity of sharing/reusing operators, the ease of experimentation, and the absence of execution and deployment friction render DeepCortex an essential element of 10x productivity gains.
The list of problems that AI can dramatically improve has become endless, but the friction of doing AI often gets in the way. Like Henry Ford’s factory streamlining the complicated production of automobiles, DeepCortex plummets the organizational cost of producing – or even mass-producing – AI.